다양한 시계열 데이터를 다루는 작업에 있어서, 수 많은 문제에 부딪히고는 한다.
여기서는 시계열 데이터의 "결측" 에 대해 다루려고 한다.
예를들어 같은 시간에 측정된 1분 간격의 기온, 기압, 수온 등의 자료를 함께 다루고자 할때 "기온"자료에서 순간적인 결측이 발생하여 각 데이터 길이가 다르게 되면 처리가 꼬이는 일이 발생하게 된다.
따라서 본 게시글에서는 결측 즉, 빈 구간의 시간값을 만들어 채우고, 데이터 길이를 맞추는 것을 해볼 것이다.
1. 필요 모듈 import
import numpy as np
import pandas as pd
import glob
import os
import datetime2. timeseries자료 불러오기
input_file='./example.csv'
df=pd.read_csv(input_file)본 코드의 실행을 위해 결측이 존재하는 1분 간격 데이터 파일을 만들어 불러왔다.
처리 전 데이터의 경우 길이가 14이다. 이후 처리 후 데이터 길이를 살펴볼 것이다.
Date value
0 2021-01-01 0:01 1.5
1 2021-01-01 0:02 1.8
2 2021-01-01 0:03 2.1
3 2021-01-01 0:13 2.2
4 2021-01-01 0:14 1.8
5 2021-01-01 0:15 2.8
6 2021-01-01 0:16 3.1
7 2021-01-01 0:19 1.7
8 2021-01-01 0:20 2.2
9 2021-01-01 0:21 1.5
10 2021-01-01 0:22 3.3
11 2021-01-01 0:23 2.4
12 2021-01-01 0:24 2.8
13 2021-01-02 1:32 3.5
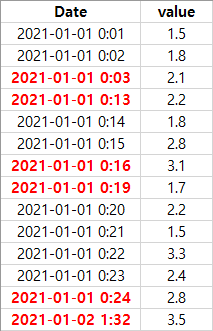
위 데이터를 살펴보면 빨간 글씨로 표시된 시간에서 결측이 존재하여 1분 간격이 아닌 그 이상의 간격을 보이고 있다.
따라서, 해당 값들의 사이에 1분 간격의 시간 열을 만들어 각각 채워줄 것이다.
3. 데이터 처리하기
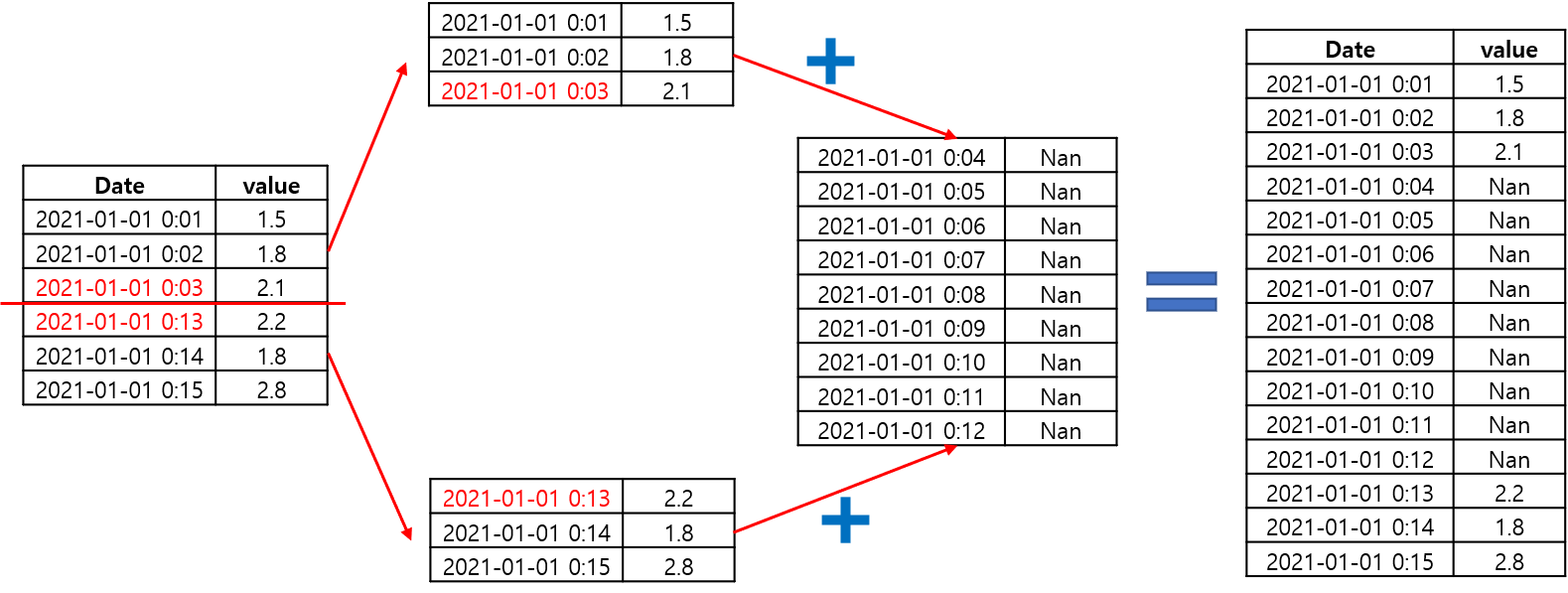
데이터의 Date열을 위부터 훑어내려가면서 앞뒤 시간차가 1분을 초과하게되면 결측이 존재하는 것이므로 해당 구간에서 작업을 수행하며 내려가도록 할 것이다.
Date열을 str type에서 시간 계산이 가능하도록 datetime type으로 만들어준다
df['Date']=pd.to_datetime(df['Date'])
while문 안에는 다음과 같은 과정이 들어간다.
1. 결측 구간에서 생성해줄 새로운 시간이 들어가게 될 list인 time_list를 만들어준다.
2. 데이터프레임을 차례로 훑으며 p행과 p+1행의 시간 차이가 1분을 초과할 경우 (그 시간의 차이)*1분 만큼의 시간을 생성하여 time_list에 넣어준다.
3. 새로 생성된 시간의 value값은 결측이므로 np.nan값으로 채워준 후 하나의 데이터프레임으로 만든다
4. 결측 구간의 데이터프레임 index를 기억하고 있으므로, 해당 index에서 데이터프레임을 반으로 가른 후 새로 생성해준 시간열을 삽입한 후 다시 붙히는 형식을 반복하게 된다.
while True:
time_list=[]
for p in range(len(df)-1):
if (df['Date'][p+1]-df['Date'][p]).seconds/60>1:
for t in range(int((df['Date'][p+1]-df['Date'][p]).seconds/60)+int(
(df['Date'][p+1]-df['Date'][p]).days*24*60)-1):
time_list.append(df['Date'][p]+datetime.timedelta(minutes=1*(t+1)))
break
length=len(time_list)
input_date=time_list
input_value=[np.nan for x in range(len(time_list))]
new_data=pd.DataFrame({'Date':input_date,
'value':input_value
})
idx = p+1
temp1 = df[df.index < idx]
temp2 = df[df.index >= idx]
df = temp1.append(new_data,ignore_index=True).append(temp2, ignore_index=True)
idx=idx
if length==0:
break
df.to_csv(input_file[:-4]+'_processed.csv',index=False)처리 전 데이터의 길이는 14였으나, 처리 후 데이터 길이는 1532로 비어있는 시간이 모두 생성되었고, value도 Nan값으로 잘 채워진 것을 확인 할 수 있다.
Date value
0 2021-01-01 00:01:00 1.5
1 2021-01-01 00:02:00 1.8
2 2021-01-01 00:03:00 2.1
3 2021-01-01 00:04:00 NaN
4 2021-01-01 00:05:00 NaN
... ...
1527 2021-01-02 01:28:00 NaN
1528 2021-01-02 01:29:00 NaN
1529 2021-01-02 01:30:00 NaN
1530 2021-01-02 01:31:00 NaN
1531 2021-01-02 01:32:00 3.5이와 같은 방식으로 각 데이터끼리의 시간에 따른 통계분석, 경향분석 등을 할때 결측에 의해 동기간 관측이더라도 데이터 길이가 달라지는 경우가 발생하고, 제대로된 처리가 되지 않는 경우가 종종 있었다.
하지만 이렇게 데이터 길이를 서로 맞추어 준다면 조금 더 수월한 분석이 가능하지 않을까 싶다.
'Python > Data 처리' 카테고리의 다른 글
| [python] GIF 그래프 만들어 보기 (0) | 2021.06.06 |
|---|---|
| [python] OPEN API 데이터 불러오기 (JSON to Pandas DataFrame) (0) | 2021.05.19 |
| [python] NOAA sea temperature netCDF4(nc)파일을 이용한 데이터 시각화 (contour plot) (2) | 2021.04.27 |



댓글